|
 |
 |
|
 |
|
|
|
|
|
|
Whatsoever thy hand findeth to do, do it with thy might; for there is no work, nor device, nor knowledge, nor wisdom, in the grave, whither thou goest, Ecclesiastes 9:10.
Coding Theory is the use of algebraic techniques to protect data transmission affected by noise, e.g., human error, imperfect or noisy channels, interference, etc.
The communication that occurs in our day-to-day life is in the form of signals. These signals, such as sound signals, generally, are analog in nature. However, digital communications are often transmitted as a sequence of binary numbers.

When the communication needs to be established over a distance, then the analog signals are sent through wire. The conventional methods of communication used analog signals for long distance communications, which suffer from many losses such as distortion, interference, and security breaches.
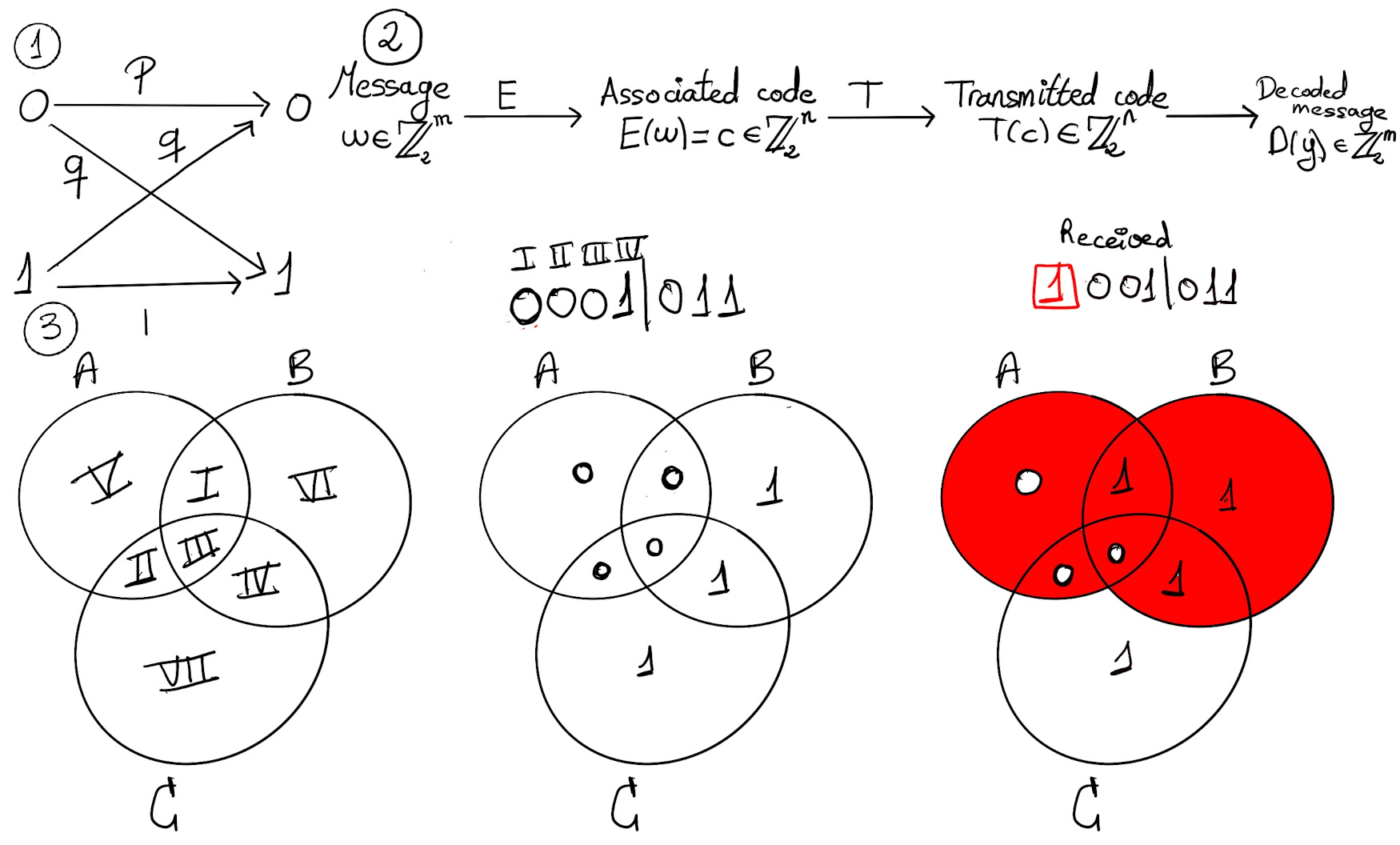
A binary symmetric channel T is a model used in coding theory. In this model, a transmitter wishes to send a binary signal, and the receiver will receive a bit. Let p be the probability that a bit is transmitted correctly, and q = 1-p is the probability that a bit is flipped, that is, transmitted incorrectly (Figure 1).
This is an example of a Bernoulli trial, that is, a random experiment with exactly two possible outcomes, “success” and “failure”, in which the probability of success is the same every time the experiment is conducted.
Let X be the random variable which counts the number of failures, the probability that k errors will occur if n bits are transmitted through the binary symmetric channel T is: $P(X=k)={n \choose k}p^{n-k}q^k$
Example. Let p = 0.995, n = 500, that is, the message is 500 bits long:
A sequence of m-bits b1b2…bm can be identified naturally with the m-tuple (b1, b2, …, bm) ∈ $ℤ_2^m$
An (n, m)-block code C could be understood as a subset of $ℤ_2^n$ paired with two functions E: $ℤ_2^m → ℤ_2^n$ and D: $ℤ_2^n → ℤ_2^m$, called the encoding and decoding function respectively, such that E is injective, D∘E = $Id_{ℤ_2^m}$, and $E(ℤ_2^m)=C.$ We call the elements of C codewords.
This is the typical model of communication system (Figure 2):
Ideally, D∘T∘E = $Id_{ℤ_2^m}$, but it will not always be possible since T is not a mathematical function, but typically there would be some errors or random noise.
A k-error detecting code is a code which reports an error when D∘T∘E ≠ $Id_{ℤ_2^m}$ for k or fewer errors, but there is no guarantee to correct those errors. An l-error correcting code is a code for which D∘T∘E = $Id_{ℤ_2^m}$ even in the presence of l or fewer errors.
ASCII, abbreviated from American Standard Code for Information Interchange, is a character encoding standard for electronic communication. It is an (8, 7)-block code, yielding 28 possible codewords.
Originally based on the English alphabet, ASCII encodes 128 characters into seven-bit integers. Most of the encoded characters are printable and include the digits, lowercase letters a to z, uppercase letters A to Z, and punctuation symbols. The eight bit, placed on the left, is called the parity check bit, and it is the sum of the other seven bits modulo n.
| Character | Decimal | Binary | ASCII |
|---|---|---|---|
| A | 65 | 1000001 | 0100 0001 |
| B | 66 | 1000010 | 0100 0010 |
| C | 67 | 1000011 | 1100 0011 |
The mappings E: ℤ27 → ℤ28, E(b1, b2,…b7) = (b1 + b2 + …+ b7 (mod 2), b1, b2,…b7), D: ℤ28 → ℤ27, D(c1, c2,…c8) = (c2, c3,…c8) are the encoding and decoding mapping respectively. ASCII forms a code which can detect a single error in a transmission. Unfortunately, this code cannot detect the presence of two or more error.
Let’s see ASCII in action. Let E(w) = 0100 0001 = c, T(c) = 0100 1001, then we have an even number of ones (“3”), but the parity check bit is a zero!!! However, T(c) = 0100 1101 is also incorrect, but the code is unable to detect it 😞
This (3m, m)-block code is a 1 error correcting code, and if there is an error with a bit, the code can correct itself by checking and outputting the most common value. However, because of its low code rate (ratio between useful information or data and actual transmitted symbols) and the fact that it cannot detect nor correct if two or more errors occur for the same bit, other error correction codes are preferred in most cases.
The Hamming (7, 4) code. A message consists of all possible 4-tuples of 0s and 1s, (x1, x2, x3, x4). Encoding will be done by multiplying each of this messages (24 = 16) on the right (these messages will be interpreted as 1 x 4 matrices with entries from ℤ2) by the matrix G, that is possible since 1 x 4 · 4 x 7 = 1 x 7.
$[ \left( \begin{smallmatrix}x_1& x_2& x_3& x_4\end{smallmatrix} \right) G = \left(\begin{smallmatrix}x_1& x_2& x_3& x_4\end{smallmatrix} \right)\left( \begin{smallmatrix}1 & 0 & 0 & 0 & 1 & 1 & 0\\ 0 & 1 & 0 & 0 & 1 & 0 & 1\\0 & 0 & 1 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 0 & 1 & 1\end{smallmatrix} \right) ]$
Examples:
$[ \left(\begin{smallmatrix}0 & 0 & 0 & 1\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 0 & 0 & 0 & 1 & 1 & 0\\ 0 & 1 & 0 & 0 & 1 & 0 & 1\\0 & 0 & 1 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 0 & 1 & 1\end{smallmatrix} \right) = \left(\begin{smallmatrix}0 & 0 & 0 & 1 & 0 & 1 & 1\end{smallmatrix} \right), \left(\begin{smallmatrix}0 & 0 & 1 & 0\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 0 & 0 & 0 & 1 & 1 & 0\\ 0 & 1 & 0 & 0 & 1 & 0 & 1\\0 & 0 & 1 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 0 & 1 & 1\end{smallmatrix} \right) = \left(\begin{smallmatrix}0 & 0 & 1 & 0 & 1 & 1 & 1\end{smallmatrix} \right), \left(\begin{smallmatrix}0 & 1 & 1 & 1\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 0 & 0 & 0 & 1 & 1 & 0\\ 0 & 1 & 0 & 0 & 1 & 0 & 1\\0 & 0 & 1 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 0 & 1 & 1\end{smallmatrix} \right) = \left(\begin{smallmatrix}0 & 1 & 1 & 1 & 0 & 0 & 1\end{smallmatrix} \right) ]$
The reader should take into consideration that:
This code can be illustrated with Venn diagrams. Begin by placing the four message digits in the four regions I, II, III, and IV, with the digit in position 1 in region 1 (e.g., 0), the digit in position 2 in region 2 (e.g., 0), and so on. V, VII, and VII are assigned 0s or 1s so that the number of 1s in each circle is even.
When there is an error (e.g., 1001011), we can detect that the regions A and B have an odd number of ones, e.g., the regions A and B have 1 and 3 respectively number of ones.
Definition. An (n, k) linear code over a finite field F is a k-dimensional subspace V of the vector space Fn = F ⊕ F ⊕ ··· ⊕ F such that the elements in V are the code words. When F is ℤ2, we have a binary code.
An (n, k) linear code over F (say F is a finite field of order q, |F| = q) is a set of n-tuples consisting of two parts: the message part (k digits, so we have qk code words since every element of the code is uniquely expressed as a linear combination of the k basis vectors with coefficients from F) + the redundancy part (n -k remaining digits).
Examples: The Hamming (7, 4) is a binary code, the set {0000, 0101, 1010, 1111} is a (4,2) binary code. The set {0000, 0121, 0212, 1022, 1110, 1201, 2011, 2102, 2220} is a (4,2) linear code over ℤ3.
The Hamming distance between two vectors in Fn is the number of components in which they differ. In particular, x, y ∈ ℤ2n, the Hamming distance between x and y is the number of positions or bits in which x and y differ, e.g., x = 0011, y = 1010, its Hamming distance is d(x, y) = 2.
The Hamming weight of a vector wt(u), u ∈ Fn is the number of nonzero entries in u. In particular, the weight of x in ℤ2n, denoted by w(x), is the total number of 1’s in x (1 is the only symbol that is different from 0 in ℤ2), e.g., w(x) = w(y) = 2. Futhermore, d(u, v) = wt(u-v) (d(u, v) and wt(u-v) both equal the number of positions in which u and v differ).
The Hamming weight of a linear code is the minimum weight of any nonzero vector in the code. The minimum distance of a code C, denoted dmin is the minimum of all Hamming distances d(x, y) where x and y are distinct codewords in C.
Example. The Hamming distance of a code. Consider the code = {c0, c1, c2, c3}, where c0 = (000000), c1 = (101101), c2 = (010110), c3 = (111011). This code has a minimum distance d = 3 because 3 = min{d(c0, c1), d(c0, c2), d(c0, c3), d(c1, c2), d(c1, c3), d(c2, c3)} = min{4, 3, 5, 5, 3, 4}. Futhermore, w(c0) = 0, w(c1) = 4, w(c2) = 3, w(c3) = 5.
Definition. A metric space is an ordered pair (M, d) where M is a set and d is a metric on M, i.e., a function d: M x M → ℝ, satisfying the following axioms ∀x, y, z ∈ M,
Theorem. The Hamming distance is a metric (a distance function) in Fn.
Proof.
To see that wt(u -w) ≤ wt(u -v) + wt(v -w), realize that if (for any arbitrary i) ui, wi are different (u and w differ in the ith position), then ui, vi or vi, wi are different (otherwise, ui=vi and vi=wi ⇒ ui=wi ⊥)
Theorem. Suppose the Hamming weight of a linear code is at least 2t + 1. Then, it can correct any t or fewer errors. Futhermore, it can be used to detect 2t or few errors.
Proof.
We are going to use the nearest neighbor decoding. Suppose u is transmitted and v is received. Decode it as the nearest code word, that is, we will assume that the corresponding code word sent is a code word v’ such that the Hamming distance d(v, v’) is a minimum.
If there is more than one such v’, do not decode. There are too many errors.
Suppose that there is no more than t errors, so that d(u, v) ≤ t. Let w be a code word other than u.
[By assumption, the Hamming weight of the linear code is at least 2t + 1, that is, ∀u, w, u ≠ w] 2t + 1 ≤ d(u, w) ≤ d(u, v) + d(v, w) ≤ [We are supposing that there is no more than t errors] t + d(v, w) ⇒ t + 1 ≤ d(v, w) ⇒ If w is a code word other than u (u ≠ w), d(v, w) > t, but d(u, v) ≤ t that is, the closest word to the received v is u, and v is correctly decoded as u.
Futhermore, if u is transmitted as v with at least one error, but fewer than 2t error, then it cannot be another code word since d(u, v) ≤ 2t and, by assumption, the minimum distance between distinct code words is at least 2t + 1. Because only code words are transmitted, errors will be detected whenever a received word is not a code word.
Remark. Suppose the Hamming weight of a linear code is at least 2t + 1. We can correct any t or fewer errors or detect 2t or few errors, but we cannot use it to do both simultaneously, e.g., the Hamming (7, 4) code’s weight is 3 = 2·1 + 1, t = 1, so we may decide either to detect any one or two errors and refuse to code or correct and decode any single error.
Suppose that we receive 1101011, there are two options:
We encode a word (x1···xk) as
$[ \left( \begin{smallmatrix}x_1& x_2& ···& x_k\end{smallmatrix} \right) G = \left(\begin{smallmatrix}x_1& x_2& ···& x_k\end{smallmatrix} \right)\left( \begin{smallmatrix}1 & 0 & ··· & 0 | & a_{11} & ··· & a_{1n-k}\\ 0 & 1 & ··· & 0 | & a_{21} & ··· & a_{2n-k}\\· & · & ··· & · | & · & · & ·\\· & · & ··· & · | & · & · & ·\\· & · & ··· & · | & · & · & ·\\ 0 & 0 & ··· & 1 | & a_{k1} & ··· & a_{kn-k}\end{smallmatrix} \right) ]$ where G = {Ik | A}. It carries a subspace V of Fk to a subspace of Fn, and the vector vG will agree with v in the first k components and will use the last n-k components to create some redundancy for error detection or correction.
In other words, the first k digits are the message digits. Such an (n, k) linear code is called a systematic code, and the matrix is called the standard generator matrix.
$[ \left( \begin{smallmatrix}x_1& x_2& x_3\end{smallmatrix} \right) G = \left(\begin{smallmatrix}x_1& x_2& x_3\end{smallmatrix} \right)\left( \begin{smallmatrix}1 & 0 & 0 & 1 & 1 & 0\\ 0 & 1 & 0 & 1 & 0 & 1\\0 & 0 & 1 & 1 & 1 & 1\end{smallmatrix} \right) ]$
The reader should realize that all nonzero code words have weight at least 3 ⇒[Theorem. Suppose the Hamming weight of a linear code is at least 2t + 1. Then, it can correct any t or fewer errors. Futhermore, it can be used to detect 2t or few errors. t = 1] It will correct single errors or detect up to two errors.
$[ \left( \begin{smallmatrix}x_1& x_2\end{smallmatrix} \right) G = \left(\begin{smallmatrix}x_1& x_2\end{smallmatrix} \right)\left( \begin{smallmatrix}1 & 0 & 2 & 1\\0 & 1 & 2 & 2\end{smallmatrix} \right) ]$
All nonzero code words have weight at least 3 ⇒ It will correct single errors or detect up to two errors.
Suppose that V is a systematic linear code over the field F given by the standard generator matrix G = $\left( \begin{smallmatrix}1 & 0 & ··· & 0 | & a_{11} & ··· & a_{1n-k}\\ 0 & 1 & ··· & 0 | & a_{21} & ··· & a_{2n-k}\\· & · & ··· & · | & · & · & ·\\· & · & ··· & · | & · & · & ·\\· & · & ··· & · | & · & · & ·\\ 0 & 0 & ··· & 1 | & a_{k1} & ··· & a_{kn-k}\end{smallmatrix} \right)$ = [Ik | A], Ik is the identity matrix k x k. Let H = [$\begin{smallmatrix}-A\\ I{n-k}\end{smallmatrix}$] be the parity-check matrix for V.
The decoding algorithm is as follows:
Example. Let us consider the Hamming (7, 4) code given by the standard generator matrix $G = \left( \begin{smallmatrix}1 & 0 & 0 & 0 & 1 & 1 & 0\\ 0 & 1 & 0 & 0 & 1 & 0 & 1\\0 & 0 & 1 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 0 & 1 & 1\end{smallmatrix} \right)$ and the corresponding parity-check matrix, $H = \left( \begin{smallmatrix}-A\\ I{n-k}\end{smallmatrix} \right) = \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 1 & 1 & 1 \\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right)$
If w = 0000110 is received, then $wH = \left( \begin{smallmatrix}0\\ 0\\ 0\\ 0\\ 1 \\ 1\\ 0\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 1 & 1 & 1 \\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right) = \left( \begin{smallmatrix}1\\ 1\\ 0\end{smallmatrix} \right)$ is the first row of H ⇒ [We assume that an error has occurred in the transmission in the first position of v] we decode it as (000110) - (1000000) = 1000110 ⇒ The original message is 1000.
If w = 1011111 is received, then $wH = \left( \begin{smallmatrix}1\\ 0\\ 1\\ 1\\ 1 \\ 1\\ 1\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 1 & 1 & 1 \\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right) = \left( \begin{smallmatrix}1\\ 0\\ 1\end{smallmatrix} \right)$ is the second row of H ⇒ [We could assume that an error has occurred in the transmission in the second position of v] we decode it as (1011111) - (0100000) = 1111111 ⇒ The original message is 1111.
If u = 1001101 is sent, and z = 1001011 is received ⇒$zH = \left( \begin{smallmatrix}1\\ 0\\ 0\\ 1\\ 0 \\ 1\\ 1\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 1 & 1 & 1 \\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right) = \left( \begin{smallmatrix}1\\ 1\\ 0\end{smallmatrix} \right)$, the first row. We will wrongly decode it as 0001011, and assume the original message was 0001.
Orthogonality Lemma. Let C be a systematic (n, k) linear code over F with a standard generator matrix G and parity-check matrix H. Then, ∀v ∈ Fn, v ∈ C ↭ vH = 0.
Proof.
G = $\left( \begin{smallmatrix}1 & 0 & ··· & 0 | & a_{11} & ··· & a_{1n-k}\\ 0 & 1 & ··· & 0 | & a_{21} & ··· & a_{2n-k}\\· & · & ··· & · | & · & · & ·\\· & · & ··· & · | & · & · & ·\\· & · & ··· & · | & · & · & ·\\ 0 & 0 & ··· & 1 | & a_{k1} & ··· & a_{kn-k}\end{smallmatrix} \right)$ = [Ik | A], Ik is the identity matrix k x k, H = [$\begin{smallmatrix}-A\\ I{n-k}\end{smallmatrix}$] has rank n - k, so we may think that H is a linear transformation from Fn onto Fn-k ⇒ [Theorem Dimension Formula. Let L: V → W be a linear transformation with V a finite-dimensional vector space, then dim(V) = dim(ker(L)) + dim(Img(L)) = dim(Ker(L)) + rank(L)] n = dim(Ker(H)) + (n-k) ⇒ dim(Ker(H)) = k.
GH = [Ik | A] [$\begin{smallmatrix}-A\\ I{n-k}\end{smallmatrix}$] = -A + A = [0] 🚀
By construction, ∀v ∈ C, v = mG where m is a message vector ⇒ vH = (mG)H = m(GH) =[🚀] m[0] = 0 ⇒∀v ∈ C, v ∈ Ker(H) ⇒ C ⊆ Ker(H) ⇒ [dim(Ker(H)) = k = dim(C)] C = Ker(H), that is, v ∈ C ↭ vH = 0∎
Theorem. Parity-check matrix decoding will correct any single error iff if the rows of the parity-check matrix are nonzero and no one row is a scalar multiple of any other.
Proof (only the binary case)
Let H be the parity-check matrix, suppose that the rows are non-zero and distinct (we are going to demonstrate only the binary case), and the transmitted code word v was received with only one error in the ith position, say w.
Let ei be the vector that has a 1 in ith position and 0s elsewhere (0 ··· 1ith position or place ··· 0), so we may rewrite the received word as w = v + ei (for simplicity’s sake, we are working only in the binary case) ⇒ [By the previous lemma, ∀v ∈ Fn, v ∈ C ↭ vH = 0, therefore vH = 0] wH = (v + ei)H = vH + eiH = 0 + eiH = eiH, and this is precisely the ith row of H. Thus, if there is exactly one error in transmission, we can use the rows of the parity-check matrix not only to identify, but to correct the location of the error, provided that these rows are distinct. Of course, if two rows are the same, say the ith and jth rows, then we can tell that an error has indeed occurred, but we do not know in which row, that is, we cannot correct it.
Conversely, let’s suppose that the parity-check matrix method correctly decodes and corrects words in which at most one error has occurred. For the sake of contradiction, let’s suppose the ith row of the parity-check matrix H was the zero vector. If the codeword v = 0···0 is sent, and an error changes the ith bit, resulting in the message ei being transmitted, the receiver could not detect the error because wH = (v + ei)H = vH + eiH = 0 + eiH = eiH = 0···0 = ith row of H, and erroneously concludes that the message ei was sent ⊥
Let’s suppose that the ith and jth rows of H are equal, i ≠ j. When the codeword 00··· 0 is sent, and an error changes the ith bit, resulting in the message ei being received, wH = (v + ei)H = vH + eiH = 0 + eiH = eiH= 0···0 = ith row of H = jth row of H ⇒ our decoding algorithm tell us not to decode ⊥ (By assumption, the parity-check matrix method correctly decodes and corrects words in which at most one error has occurred).
Let’s consider the fact that an (n, k) linear code C over a finite field F is a subgroup of the additive group of V = Fn.
Consider the (6,3) binary linear code C = {000000, 100110, 010101, 001011, 110011, 101101, 011110, 111000}.
We are going to create a table, the standard array, as follows,
| Coset Leader | Words | ||||||
|---|---|---|---|---|---|---|---|
| 000000 | 100110 | 010101 | 001001 | 110011 | 101101 | 011110 | 111000 |
| Coset Leader | Words | ||||||
|---|---|---|---|---|---|---|---|
| 000000 | 100110 | 010101 | 001011 | 110011 | 101101 | 011110 | 111000 |
| 100000 | 000110 | 110101 | 101011 | 010011 | 001101 | 111110 | 011000 |
| Coset Leader | Words | ||||||
|---|---|---|---|---|---|---|---|
| 000000 | 100110 | 010101 | 001011 | 110011 | 101101 | 011110 | 111000 |
| 100000 | 000110 | 110101 | 101011 | 010011 | 001101 | 111110 | 011000 |
| 010000 | 110110 | 000101 | 011001 | 100011 | 111101 | 001110 | 101000 |
| 001000 | 101110 | 011101 | 000011 | 111011 | 100101 | 010110 | 110000 |
| 000100 | 100010 | 010001 | 001111 | 110111 | 101001 | 011010 | 111100 |
| 000010 | 100100 | 010111 | 001001 | 110001 | 101111 | 011100 | 111010 |
| 000001 | 100111 | 010100 | 001010 | 110010 | 101100 | 011111 | 111001 |
| 100001 | 000111 | 110100 | 101010 | 010010 | 001100 | 111111 | 011001 |
The decoding algorithm is quite simple. One can decode a received word as the code word (first row) in the vertical column containing the received word, e.g., 101001, 101100, and 001100 are decoded as 101101; 011000, 101000, and 011001 are decoded as 111000.
Theorem. The coset decoding is the same algorithm as nearest-neighbor decoding.
Proof.
Let C be a linear code (i.e., our coset), w be a received word. If v is the coset leader of the coset containing w, then w + C = v + C ⇒ ∃c ∈ C: w = v + c, and w is decoded as c.
Let c’ be any arbitrary code word (c’∈ C) ⇒ w - c’ ∈ w + C = v + C ⇒ [By assumption, the coset leader v was chosen as a vector of minimum weight among the members of v + C] wt(w - c’) ≥ wt(v) ⇒ d(w, c’) = wt(w - c’) ≥ wt(v) = wt(w -c) = d(w, c). Therefore, w is decoded as the code word c which has minimum distance to w among all code words.
Definition. Let C be an (n, k) linear code over F with a parity-check matrix H. Given any vector u ∈ Fn, the vector uH is called the syndrome of u.
Theorem. Let C be an (n, k) linear code over F with a parity-check matrix H. Then, two vectors of Fn are in the same coset of C if and only if they have the same syndrome.
Proof:
Let u, v ∈ Fn are in the same coset of C ↭ u - v ∈ C ⇒ [By the Orthogonality Lemma ∀v ∈ Fn, v ∈ C ↭ vH = 0.] u and v are in the same coset ↭ 0 = (u -v)H = uH -vH ↭ uH = vH, that is, they both have the same syndrome.
Syndrome decoding for a received word w:
Example.
$H = \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right).$
$\left( \begin{smallmatrix}1\\ 0\\ 0\\ 0 \\ 0\\ 0\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right) = \left( \begin{smallmatrix}1\\ 1\\ 0\end{smallmatrix} \right)$
| Coset leader | 000000 | 100000 | 010000 | 001000 | 000100 | 000010 | 000001 | 100001 |
|---|---|---|---|---|---|---|---|---|
| Syndromes | 000 | 110 | 101 | 011 | 100 | 010 | 001 | 111 |
To decode w = 101001,
$wH=\left( \begin{smallmatrix}1\\ 0\\ 1\\ 0 \\ 0\\ 1\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right) = \left( \begin{smallmatrix}1\\ 0\\ 0\end{smallmatrix} \right) = \left( \begin{smallmatrix}0\\ 0\\ 0\\ 1 \\ 0\\ 0\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right) $ ⇒ w - v (coset leader) = (101001) - (000100) = 101101 was the original message sent.
To decode w = 011001,
$wH=\left( \begin{smallmatrix}0\\ 1\\ 1\\ 0 \\ 0\\ 1\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right) = \left( \begin{smallmatrix}1\\ 1\\ 1\end{smallmatrix} \right) = \left( \begin{smallmatrix}1\\ 0\\ 0\\ 0 \\ 0\\ 1\end{smallmatrix} \right) \left( \begin{smallmatrix}1 & 1 & 0\\1 & 0 & 1\\ 0 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{smallmatrix} \right) $ ⇒ w - v (coset leader) = (011001) - (100001) = 111000 was the original message sent.

JustToThePoint Copyright © 2011 - 2024 Anawim. ALL RIGHTS RESERVED. Bilingual e-books, articles, and videos to help your child and your entire family succeed, develop a healthy lifestyle, and have a lot of fun. Social Issues, Join us.
This website uses cookies to improve your navigation experience.
By continuing, you are consenting to our use of cookies, in accordance with our Cookies Policy and Website Terms and Conditions of use.