|
 |
 |
|
 |
|
|
|
|
|
|
A regular expression is a specific pattern that provides concise means to specify and recognize strings of text. Python has a module named “re” to work with Perl-like regular expressions.

import re
my_text = '''
Alice was beginning to get very tired of sitting by her sister on the bank,
and of having nothing to do: once or twice she had peeped into the book her sister was reading,
but it had no pictures or conversations in it, `and what is the use of a book,'
thought Alice `without pictures or conversation?'
'''
pattern = re.compile(r'Alice')
# re.compile compiles a regular expression pattern into a regular expression object. It is used for matching.
# The 'r' at the start of the pattern string designates a python “raw” string. It is a string literal in which a backslash, "\" is taken as meaning "just a backslash".
matches = pattern.finditer(my_text)
# re.finditer returns an iterator yielding match objects.
for match in matches:
print(match)
The result is:
<re.Match object; span=(1, 6), match='Alice'>
<re.Match object; span=(264, 269), match='Alice'>
If you write: print (my_text[1:6]), it will return ‘Alice’.
Metacharacters are characters with a special meaning, e.g., [] -a set of character-, . -any character-, ^ -starts with-, $ -ends with, * -Zero or more occurrences-, + -One or more occurrences-, ? -Zero or one occurrences-, {} -Exactly the specified number of occurrences, | -either or-. They need to be escaped.
import re
my_text = '''
Alice was beginning to get very tired of sitting by her sister on the bank,
and of having nothing to do: once or twice she had peeped into the book her sister was reading,
but it had no pictures or conversations in it, `and what is the use of a book,'
thought Alice `without pictures or conversation?'
Read more books in https://justtothepoint.com/,
Free resources, bilingual e-books and videos to help your child and your entire family succeed, develop a healthy lifestyle, and have a lot of fun.
'''
pattern = re.compile(r'justtothepoint\.com')
Observe that we use the backslash to escape the dot ‘.’ We need to use it to escape any special character and interpret it literally; e.g., \., \\, or \{ escapes the dot ‘.’, the backslash ‘\’ and the open bracket ‘{’ respectively.
matches = pattern.finditer(my_text)
for match in matches:
print(match)
It will return:
<re.Match object; span=(334, 352), match='justtothepoint.com'>
import re
my_url = "https://www.youtube.com/watch?v=ceE-U1YAWo0&ab_channel=4KVideoNature-FocusMusic"```
pattern = re.compile(r'https://www\.youtube\.com/watch\?v=(\S{11})')
The YouTube video Id is ceE-U1YAWo0&ab, a unique identifier made of 11 characters. We need to escape “\.” the first and second dots (www.youtube.com), and the question mark (\?). \S is a match where the string does not contain a white space character. S{11} specifies that there are exactly 11 copies of \S, i.e., 11 no white space characters.
video_id = pattern.findall(my_url)
print(video_id[0])
Regular expressions allow us to not just match text but also to extract information, e.g., (\S{11}) the round parenthesis indicates the start and end of a group, in this particular case the YouTube video Id consisting of the 11 no white space characters following the initial part: https://www.youtube.com/watch?v=.
Groups are used to define what the regular expression has to return. It allows us to pick out parts of the matching text. On a successful search, video_id[0] is the match text corresponding to the first parenthesis.
We can specify repetition in the pattern: “+” indicates 1 or more occurrences of the pattern, “*” indicates 0 or more occurrences of the pattern, and “?”, 0 or 1.
Let’s extract the number of pages from a pattern, e.g., pages: number.
my_text = '''
Alice was beginning to get very tired of sitting by her sister on the bank,
and of having nothing to do: once or twice she had peeped into the book her sister was reading,
but it had no pictures or conversations in it, `and what is the use of a book,'
thought Alice `without pictures or conversation?'
pages: 10
[...]
'''
``` python
pages = re.search('pages: ([0-9]+)', my_text).group(1)
# On a successful search, re.search('pages: ([0-9]+)', my_text).group(1) is the match text corresponding to the first parenthesis
# Square brackets are used to indicate a set of chars, e.g., [abc12] matches ‘a’, ‘b’, ‘c’, '1', or '2'.
# We use a dash "-" to indicate a range, so [0-9] matches all digits, the '+' indicates 1 or more occurrences of the pattern.
print(pages)
Now, we will use re.sub() to replace substrings in strings:
import re
my_text = '''
Alice was beginning to get very tired of sitting by her sister on the bank,
and of having nothing to do: once or twice she had peeped into the book her sister was reading,
but it had no pictures or conversations in it, `and what is the use of a book,'
thought Alice `without pictures or conversation?'
Read more books in http://justtothepoint.com/, nunez-231-maximo@gmail.com,
Free resources, bilingual e-books and videos to help your child and your entire family succeed, develop a healthy lifestyle, and have a lot of fun.
Mr Maximo Núñez
Mr. Máximo
pages: 10, id: my_id_text, oldPhone1: 659-34-12-24, myWeb: http://justtothepoint.com
oldPhone2: 345.12.23.24, oldEmail: nunez@uma.edu, oldWeb: http://www.justtothepoint.com
'''
my_text = re.sub(r"[a-zA-Z0-9-.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+", "myemail@gmail.com", my_text)
my_text = re.sub(r"https?://(www\.)?(\w+)(\.\w+)", "https://justtothepoint.com/", my_text)
https? means that it can match “http” or “https”. Next, the colon and double-slash ://. (www.)? The website can be defined as www.mywebsite.com or mywebsite.com. So, www. is optional, too.
As for the domain, this is the pattern: (\w+)(\.\w+). \w (word character) matches any single letter, number or underscore, + means that there is one or more characters. A domain consists of two parts, a second level domain (the name of the website) and a top level domain. If we know that our domain extension has only three characters (e.g., .com, .edu, .org, but be aware that this code will not work with .co, .us, or .es), we can replace this line of code by: my_text = re.sub(r"https?://(www\.)?(\w+)(\.\w{3})", “https://justtothepoint.com/”, my_text).
my_text = re.sub(r"pages: [0-9]+,", "pages: 15.", my_text)
my_text = re.sub(r"\d\d\d[.-]\d\d[.-]\d\d[.-]\d\d", "659-35-24-12", my_text)
my_text = re.sub(r"Mr\.?\s[A-Z]\w*(\s[A-Z]\w*)?", "PhD. Máximo Núñez Alarcón, Anawim", my_text)
print(my_text)
The result is as follows:
Alice was beginning to get very tired of sitting by her sister on the bank,
and of having nothing to do: once or twice she had peeped into the book her sister was reading,
but it had no pictures or conversations in it, and what is the use of a book,' thought Alice without pictures or conversation?’
Read more books in https://justtothepoint.com//, myemail@gmail.com, Free resources, bilingual e-books and videos to help your child and your entire family succeed, develop a healthy lifestyle, and have a lot of fun. PhD. Máximo Núñez Alarcón, Anawim PhD. Máximo Núñez Alarcón, Anawim pages: 15. id: my_id_text, oldPhone1: 659-35-24-12, myWeb: https://justtothepoint.com/ oldPhone2: 659-35-24-12, oldEmail: myemail@gmail.com, oldWeb: https://justtothepoint.com/
domain = re.search(r"https?://(www\.)?(\w+)(\.\w{3})", "https://justtothepoint.com/en/library/index.html").group(2)
top_level = re.search(r"https?://(www\.)?(\w+)(\.\w{3})", "https://justtothepoint.com/en/library/index.html").group(3)
if re.search(r"https?://(www\.)?(\w+)(\.\w{3})", "https://justtothepoint.com/en/library/index.html").group(1) is None:
print("Not www found!") # It prints: Not www found!
print(domain) # It retuns justtothepoint
print(top_level) # It returns .com
def getLastDirectory(url):
protocol = re.findall( r'(\w+)://', url)[0]
domain = re.findall('://([\w\-\.]+)', url)[0]
print("Protocol: " + str(protocol) + ".", end = "")
print(" Domain: " + str(domain) + ".", end = "")
# [^/]+ Looks for at least one character that is not a slash
lastDirectory = re.findall('[^/]+(?=/$|$)', url)
# (?=pattern) is a zero-width positive lookahead assertion. For example, \w+(?=\t) matches a word followed by a tab, without including (or capturing) the tab.
# In this particular example [^/] looks for as many as possible characters that are not a slash "/".
# (?=/$|$) makes sure that the next part of the string is a slash "/" and then the end of the string "$" or (|) just the end of the string "$",
# so it matches library in https://justtothepoint.com/en/library/ or https://justtothepoint.com/en/library but it does not include the slash "/" in the match.
return lastDirectory[0]
if __name__ == '__main__':
print(" Last directory: " + getLastDirectory("https://justtothepoint.com/en/library/"))
print(" Last directory: " + getLastDirectory("https://justtothepoint.com/en/library"))
The result is as follows,
Protocol: https. Domain: justtothepoint.com. Last directory: library
Protocol: https. Domain: justtothepoint.com. Last directory: library
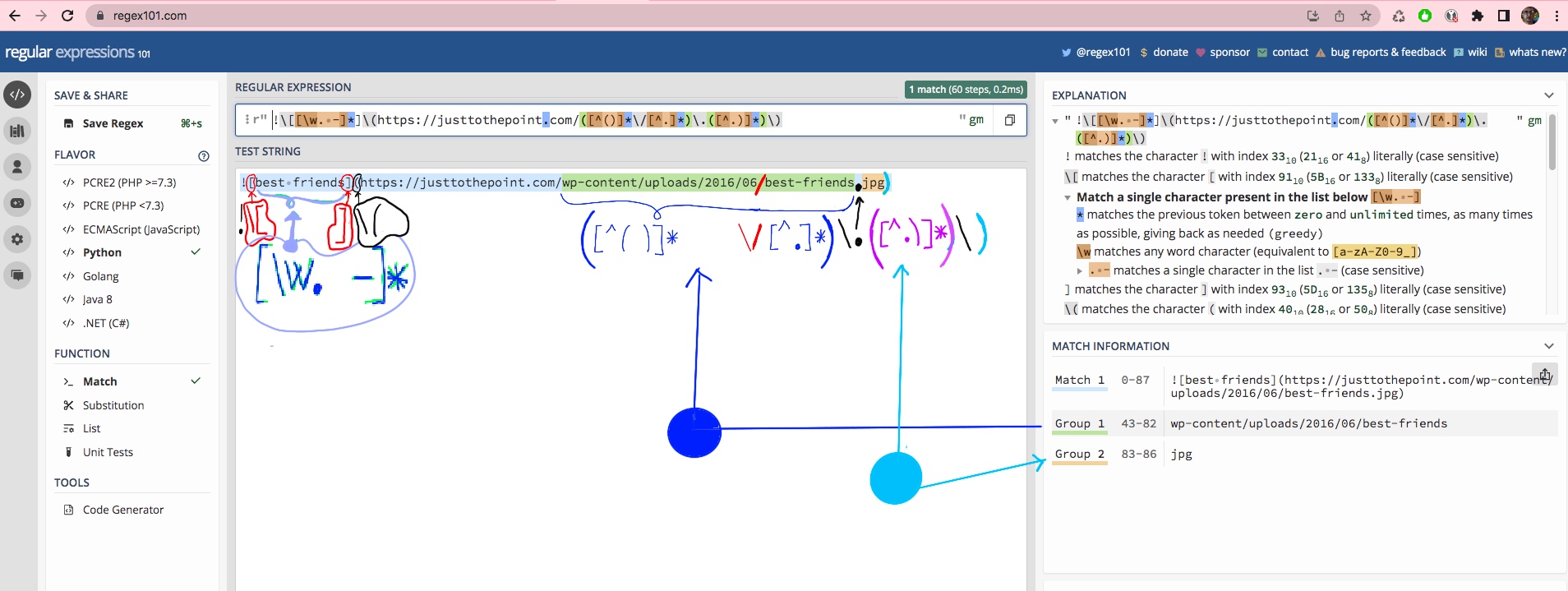
We want to rewrite images in Hugo and replace them with calls to our img shortcode. You may want to check our article about Hugo. I also want to find and replace images from the URL path (e.g., https.//justtothepoint.com/wp-content/uploads/2016/06/best-friends.jpg) to the Hugo’s relative path (../images/best-friends.jpg).
content = '''

'''
def text():
# sub(pattern, replacement, string[, count, flags]), https://pynative.com/python-regex-replace-re-sub/
maches = re.findall(r'!\[[\w. -]*]\(https://justtothepoint.com/([^()]*\/[^.]*)\.([^.)]*)\)', content)
After our website’ main URL, we start a group “(”, then include a caret (^) to invert the matching, e.g., [^()] matches everything but the opening and closing parentheses. This pattern may be repeated ("*") 0 or more times, till it finds a backlash “/” (it is escaped, too). Next [^.)] matches everything but a dot ("."). Please take notice that most metacharacters lose their special meaning inside brackets, and it is repeated 0 or more times till we find a dot “.”. This is our first group.
Then, we start a second group to extract the extension of the picture (“jpg”), and we match every character but a “.” again till we find the closing parenthesis “)” that it needs to be escaped, too!
for match in maches:
path = str(match[0]) + "."" + str(match[1])
print("File to convert: " + path)
# The pattern here is slightly different because the two groups are the name and extension of the picture: ([^.]*)\.([^.)]*)
# Therefore, we start the pattern quite the same, and we match everything but parenthesis till we find a filename (file + "." + extension).
# Then, we replace our matches with a call to our "img" shortcode.
# Observe that '\1' and '\2' refers to the text from group(1) -name- and group(2) -extension-.
print(content_new)
if __name__ == '__main__':
text()
It returns:
File to convert: wp-content/uploads/2016/06/best-friends.jpg
def myMarkdownEditing(filename, language):
with open (filename, 'r+' ) as f:
content = f.read()
content = headerEditing(content=content, language=language)
content = specialCharactersEditing(content)
f.seek(0)
f.write(content)
f.truncate()
def specialCharactersEditing(content):
# Find/replace random character strings created by escape characters, e.g., \_, \_\_, \*, \[, \], ._...
# These were created by the conversion script from WordPress to Hugo
pattern = re.compile(r'\\_')
content = pattern.sub("_", content)
pattern = re.compile(r'\\_\\_')
content = pattern.sub("__", content)
pattern = re.compile(r'\\\*')
content = pattern.sub("*", content)
pattern = re.compile(r'\\\[')
content = pattern.sub("[", content)
pattern = re.compile(r'\\\]')
content = pattern.sub("]", content)
pattern = re.compile(r'\.\_')
content = pattern.sub(".", content)
# Prevent Hugo from converting double hyphen into a dash
pattern = re.compile(r'\-\-')
content_new = pattern.sub("‐‐", content_new)
return content_new
Front matter is metadata found at the top of each Markdown post in a Hugo site. In my example it is in YAML format, so the front matter is enclosed in ‐‐‐.
def addingLine(content, pattern, newLine):
if re.search(pattern, content) is None:
# If the pattern (or the line) is not found, we add it just after the first "---", that's why there is a "1" as the last argument in re.sub.
content = re.sub(r'---', "---\n" + newLine, content, 1)
return content
# Fields in front matter can include titles, weights, languages, authors, etc.
def headerEditing(content, language):
content = addingLine(content, r"weight:", "weight:")
content = addingLine(content, r"language:", "language: " + language)
content = addingLine(content, r"author:", "author: Máximo Núñez Alarcón, Anawim")
[...]
return content
if __name__ == '__main__':
myMarkdownEditing("myMarkdown.md", "en")
fortune is a program that displays a pseudorandom message from a database of quotations. The basic format is as follows:
%
The first principle is that you must not fool yourself -- and you are the easiest person to fool.
-- Richard Feynman
%
The greater danger for most of us lies not in setting our aim too high and falling short; but in setting our aim too low, and achieving our mark.
-- Michelangelo
%
import re
with open ("quotes.txt", 'r+' ) as f:
content = f.read()
matches = re.findall(r'%\n(.*$)\n[ ]*-- (.*$)', content, re.MULTILINE)
# It starts with a percentage symbol "%" (1st line), next a new line "\n". Then, the first group, the quote itself, matches everything in the next line (.*$) -second line-
# Next, we match a new line \n, after that there are a number of spaces before the two hyphens "--": [ ]*--
# Finally, the second group, the author, matches everything before the end of this line: (.*$) -third line-
for match in matches:
print('{\n\t"author": "' + match[1] + '",')
print('\t"quote": "' + match[0] + '"\n},')
The result is as follows:
{
"author": "Richard Feynman",
"quote": "The first principle is that you must not fool yourself -- and you are the easiest person to fool."
},
{
"author": "Michelangelo",
"quote": "The greater danger for most of us lies not in setting our aim too high and falling short; but in setting our aim too low, and achieving our mark."
},
sed is a utility to search and replace text in files. Let’s say that we want to search and replace the word “linux” with “GNU,Linux”, that’s how you could achieve it:
$sed 's/linux/GNU,Linux/g' mySourceFile.txt
g performs a global search, so all matches in each line are processed. Let’s say that we want to extract lines one to three from a file:
$sed -n "1,3p" notas.txt
We can use sed to recursively replace text in multiple files:
$find /home/myUserName/JustToThePoint/content/ -name "*.md" -exec sed -i 's/linux/GNU,Linux/g' {} \;
First, we find all Markdown files in this particular directory and all its subdirectories. It results in a list of Markdown files. Next, we will execute the sed command on the resulting paths with the -exec Action.
As a result, we will search and replace the word “linux” with “GNU,Linux” in all Markdown files in a particular directory recursively, i.e., not just all Markdown files in this directory, but also in all its subdirectories.
The -exec flag includes:
A more useful examples can be found in the following articles: WordPress Advanced Administration, Optimizing Images From the Command Line, Installing Arch from Scratch, and Installing Arch from Scratch II, e.g.,
[...]
# Set up the locale, i.e., the language, numbering, date, and currency formats for your system.
sed --in-place=.bak 's/^#en_US.UTF-8 UTF-8/en_US.UTF-8 UTF-8/' /etc/locale.gen.
Sources: Regex by Examples, Python Regular Expressions Cheat Sheet, and Python Introduction, Section Regular expressions. Regular expressions 101.

JustToThePoint Copyright © 2011 - 2024 Anawim. ALL RIGHTS RESERVED. Bilingual e-books, articles, and videos to help your child and your entire family succeed, develop a healthy lifestyle, and have a lot of fun. Social Issues, Join us.
This website uses cookies to improve your navigation experience.
By continuing, you are consenting to our use of cookies, in accordance with our Cookies Policy and Website Terms and Conditions of use.