|
 |
 |
|
 |
|
|
|
|
|
|
NLTK is an amazing library to start with natural language.
Installing NLTK: 1. python -m pip install nltk==3.5. 2. python -m pip install numpy matplotlib.
>>>import nltk
Finally, we use the NLTK’s data downloader:
>>>nltk.download('wordnet')
>>>quit()
from nltk.corpus import wordnet # WordNet is a lexical database for the English language, specifically designed for natural language processing.
"""Define a word using WordNet"""
def defineWordNet(word):
try:
syns = wordnet.synsets(word) # It looks up a word and returns a list of synsets (synonymous words that express the same concept, e.g. beloved) using wordnet.synsets().
for syn in syns:
print(syn.name(), ":", syn.definition(), ".", syn.examples()) # It prints the name, definition, and examples for each synset in the list.
except:
return "No definition found."
if __name__ == '__main__':
defineWordNet("love")
love.n.01 : a strong positive emotion of regard and affection . [‘his love for his work’, ‘children need a lot of love’]
love.n.02 : any object of warm affection or devotion . [’the theater was her first love’, ‘he has a passion for cock fighting’] beloved.n.01 : a beloved person; used as terms of endearment . []
love.n.04 : a deep feeling of sexual desire and attraction . [’their love left them indifferent to their surroundings’, ‘she was his first love’] […]
from nltk.corpus import wordnet # WordNet is a lexical database for the English language, specifically designed for natural language processing.
def synonymsAntonyms(word):
antonyms = []
synonyms = []
syns = wordnet.synsets(word) # It looks up a word and returns a list of synsets
for syn in syns:
for lemma in syn.lemmas(): # A lemma is the canonical or dictionary form of a word. It represents a specific sense of a word.
synonyms.append(lemma.name().lower()) # Since all the lemmas in our list of synsets have the same meaning, they can be treated as synonyms.
if lemma.antonyms(): # We use the method antonyms() to find the antonyms for the lemmas.
antonyms.append(lemma.antonyms()[0].name().lower())
print("\nantonyms(" + word + ")", set(antonyms)) # We use sets to remove duplicates.
print("\nsynonyms(" + word + ")", set(synonyms))
if __name__ == '__main__':
synonymsAntonyms("friend")
antonyms(friend) {‘foe’, ‘stranger’}
synonyms(friend) {‘quaker’, ‘acquaintance’, ‘champion’, ‘friend’, ‘protagonist’, ‘booster’, ‘ally’, ‘supporter’, ‘admirer’}
Tokenizing is the process of diving a text into its basic meaningful entities.
user@pc:~$ python
Python 3.9.5 (default, May 11 2021, 08:20:37)
[GCC 10.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from nltk.tokenize import sent_tokenize, word_tokenize
>>> example = "I love cats and dogs very much. I like fluffy because they're cute."
>>> sent_tokenize(example) # We use sent_tokenize() to split up example into sentences.
['I love cats and dogs very much.', "I like fluffy because they're cute."]
>>> words = [word_tokenize(sentence) for sentence in sent_tokenize(example)] # We use word_tokenize() to split up sentences into words.
>>> words
[['I', 'love', 'cats', 'and', 'dogs', 'very', 'much', '.'], ['I', 'like', 'fluffy', 'because', 'they', "'re", 'cute', '.']]
Observe how they’re was split at the apostrophe to give you “they” and “’re”.
Stop words are words which are filtered out before processing your text. They are words that you want to ignore because they don’t add a lot of meaning to a text.
>>> from nltk.corpus import stopwords # nltk.corpus has a list of stopwords stored in different languages
>>> stop_words = set(stopwords.words("english")) # {'from', "weren't", 'below', 'so', 'couldn', 'for', 'had', 'doing', "couldn't", 'now', 'shouldn', 'having', 'same', 'that', 'his', 'them', 'doesn', 'me', 'to', 'shan', 'our', 'own', 'yourselves', 'or', 'do'....}
>>> import itertools
word_list = list(itertools.chain.from_iterable(words)) # word_list is a simple list of words out of a list of lists (words)
content_words = []
filtered_words = []
>>> for word in word_list: # It iterates over word_list with a for loop
... if word.lower() not in stop_words: # We use the method lower() to ignore whether the letters in word are uppercase or lowercase
... content_words.append(word)
... else:
... filtered_words.append(word)
...
>>> content_words
['love', 'cats', 'dogs', 'much', '.', 'like', 'fluffy', "'re", 'cute', '.']
>>> filtered_words
['I', 'and', 'very', 'I', 'because', 'they'] # We have filtered out a few words like "I" and "and".
Stemming is the process of reducing a word to its root or word stem.
>>> from nltk.stem import PorterStemmer # Stemmers remove morphological affixes from words, leaving only the word stem.
>>> stemmer = PorterStemmer() # It create a new Porter stemmer.
>>> stemmed_words = [stemmer.stem(word) for word in word_list]
>>> stemmed_words
['I', 'love', 'cat', 'and', 'dog', 'veri', 'much', '.', 'I', 'like', 'fluffi', 'becaus', 'they', "'re", 'cute', '.']
The process of classifying words into their parts of speech and labeling them accordingly is known as part-of-speech tagging.
>>> import nltk # Previously, you need to use the NLTK Downloader to obtain averaged_perceptron_tagger: >>> import nltk, >>> nltk.download('averaged_perceptron_tagger')
>>> nltp.pos_tag(word_list)
[('I', 'PRP'), ('love', 'VBP'), ('cats', 'NNS'), ('and', 'CC'), ('dogs', 'NNS'), ('very', 'RB'), ('much', 'RB'), ('.', '.'), ('I', 'PRP'), ('like', 'VBP'), ('fluffy', 'RB'), ('because', 'IN'), ('they', 'PRP'), ("'re", 'VBP'), ('cute', 'NN'), ('.', '.')]
``` python
nltk.help.upenn_tagset() (>>> import nltk, >>> nltk.download('tagsets')) gives you the list of tags and their meanings, e.g. VBP: verb, present tense, not 3rd person singular; NNS: noun, common, plural; CC: conjunction, coordinating.
NLTK concordance is a function to search every occurrence of a particular word in a text. It also displays the context around the search word.
>>> from nltk.book import * # It requires nltk.download("book"). It loads the text of several books.
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
>>> text3.count("multiply") # the method count() counts the total appearances of a given word in a text
18
>>> text3.concordance("multiply") # A concordance permits us to see words in context.
Displaying 18 of 18 matches: them, saying, Be fruitful, and multiply, and fill the waters in the seas waters in the seas, and let fowl multiply in the earth. And the evening and said unto them, Be fruitful, and multiply, and replenish the earth and su the woman he said , I will greatly multiply thy sorrow and thy conception;[…]
>>> text4.similar("liberty") # The similar method takes an input word and returns other words that appear in a similar range of contexts in the text.
peace government freedom power life war duty congress all them it us
progress prosperity america history civilization which time men
>>> text4.common_contexts(["liberty", "constitution"]) # The method common_contexts allows us to examine the contexts that are shared by two or more words, such as liberty and constitution.
our_and the_of # Liberty and constitution are usually surrounded by "our_and" and "the_of".
>>>> print(text2.generate()) # It prints random text, generated using a trigram language model.
Building ngram index… long, from one to the topmast, and no coffin and went out a sea captain ‐‐ this peaking of the whales. so as to preserve all his might had in former years abounding with them, they toil with their lances, strange tales of Southern whaling[…]
We can plot a lexical dispersion plot to see how much a particular word appears and where it appears. Each stripe represents an instance of a word, and each row represents the entire text.
>>> text3.dispersion_plot(
... ["man", "woman", "Abraham", "Lord", "God", "love", "multiply", "created"] ) # You need to have Python's NumPy and Matplotlib packages installed.
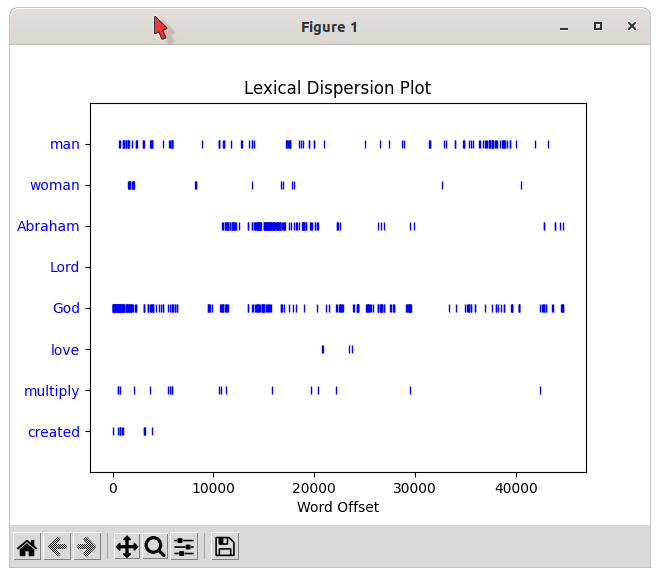
Apparently “created” is mentioned a lot in the first part of Genesis and then doesn’t come up again. There are no instances of “Lord”. The word “man” appears more times in Genesis than the word “woman".
>>> from nltk.corpus import stopwords # nltk.corpus has a list of stopwords stored in different languages
>>> import nltk
>>> from nltk.book import *
>>> stop_words = set(stopwords.words("english"))
>>> meaningful_words = []
>>> for word in text3: # It iterates over text3 with a for loop
... if word.lower() not in stop_words and word.isalnum(): # We use the method lower() to ignore whether the letters in word are uppercase or lowercase, and the method isalnum() to remove all punctuation marks
... meaningful_words.append(word)
>>> from nltk import FreqDist # A frequency distribution is used to study which words show up most frequently in a text.
>>> frequency_distribution = FreqDist(meaningful_words) # We are going to study the frequency distribution of words that are not stop words or punctuation marks.
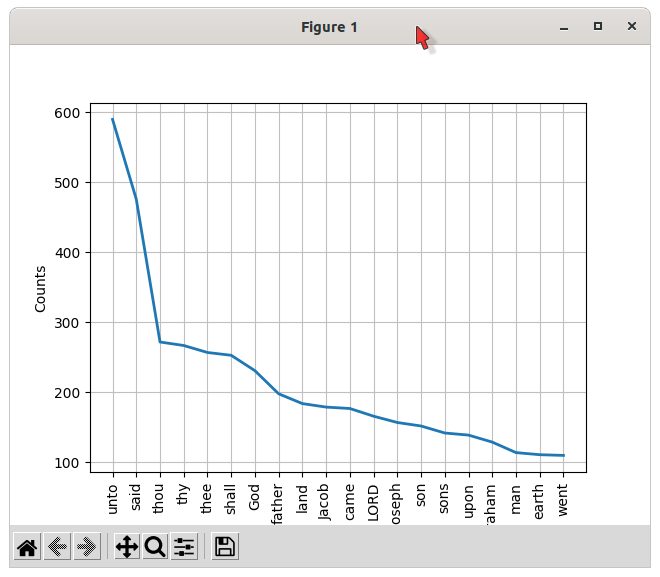
>>> frequency_distribution.most_common(20) # Furthermore, we are going to study the frequency distribution of the 20 most common words in Genesis that are not stop words or punctuation marks.
[('unto', 590), ('said', 476), ('thou', 272), ('thy', 267), ('thee', 257), ('shall', 253), ('God', 231), ('father', 198), ('land', 184), ('Jacob', 179), ('came', 177), ('LORD', 166), ('Joseph', 157), ('son', 152), ('sons', 142), ('upon', 139), ('Abraham', 129), ('man', 114), ('earth', 111), ('went', 110)]
>>> frequency_distribution.plot(20, cumulative=False) # We plot the frequency distribution of the 20 most common words in Genesis.
>>> text3.collocation_list() # A collocation is a sequence of words or terms that co-occur more often than would be expected by chance. The collocation_list method returns a list of collocation words with the default size of 2.
[('said', 'unto'), ('pray', 'thee'), ('thou', 'shalt'), ('thou', 'hast'), ('thy', 'seed'), ('years', 'old'), ('spake', 'unto'), ('thou', 'art'), ('LORD', 'God'), ('every', 'living'), ('God', 'hath'), ('begat', 'sons'), ('seven', 'years'), ('shalt', 'thou'), ('little', 'ones'), ('living', 'creature'), ('creeping', 'thing'), ('savoury', 'meat'), ('thirty', 'years'), ('every', 'beast')]
>>> len(text4) # It calculates the length of a text from start to finish
149797 # The Inaugural Address Corpus has 149797 words and punctuation symbols or tokens.
>>> len(set(text4)) # The vocabulary of a text is the set of tokens (or unique words) that it uses. The same result could have been obtained by: len(text4.vocab())
9913 # The Inaugural Address Corpus has 9913 distinct words and punctuation symbols.
>>> len(set(text4)) / len(text4) # It calculates a measure of the lexical richness of the text.
0.06617622515804722
Sentiment analysis is the process of detecting polarity (e.g. a positive or negative opinion) within a text. VADER is a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media.
>>> from nltk.sentiment import SentimentIntensityAnalyzer # It requires >>> nltk.download('vader_lexicon')
>>> sia = SentimentIntensityAnalyzer() # It creates an instance of a SentimentIntensityAnalyzer.
>>> sia.polarity_scores("Wow, this food is so tasty and yummy!")
{'neg': 0.0, 'neu': 0.436, 'pos': 0.564, 'compound': 0.8297}
We use the method polarity_scores on a string. It returns a dictionary of negative, neutral, and positive scores, and a compound score. The negative, neutral, and positive scores add up to 1 and cannot be negative. The compound score ranges from -1 to 1. Typical threshold values are: 1. positive sentiment: compound score ≥ 0.05 2. negative sentiment: compound score ≤ -0.05 3. neutral sentiment: compound score > -0.05 and compound score < 0.05.
>>> sia.polarity_scores("This is so yucky it makes me puke!")
{'neg': 0.549, 'neu': 0.451, 'pos': 0.0, 'compound': -0.8078}
>>> sia.polarity_scores("Cauliflower and broccoli are both cabbages")
{'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0}

JustToThePoint Copyright © 2011 - 2024 Anawim. ALL RIGHTS RESERVED. Bilingual e-books, articles, and videos to help your child and your entire family succeed, develop a healthy lifestyle, and have a lot of fun. Social Issues, Join us.
This website uses cookies to improve your navigation experience.
By continuing, you are consenting to our use of cookies, in accordance with our Cookies Policy and Website Terms and Conditions of use.